How FortressDigital Cut Payment Processing Failures by 87% With a Real-Time Webhook Architecture
When FortressDigital's legacy monolithic payment pipeline buckled under a tenfold load surge in mid-2024, the CTO gave engineering just 60 days to fix it without touching production. Encrypted tightly between four services via synchronous HTTP calls, the system was carrying an 18% payment failure rate that climbed higher with every new enterprise client onboarded. Retry storms from failed bank-connector calls cascaded through fraud detection, ledger posting, and settlement, leaving post-incident recovery teams spending an average of 47 minutes untangling logs just to identify the originating service. Compliance was compounding the pressure further — in the highly regulated RegTech space, every failed payment was also a compliance event. What followed was a 10-week architecture mission spanning a RabbitMQ event bus, exponential backoff with dead-letter queues, end-to-end distributed tracing via OpenTelemetry and Jaeger, and circuit-breaker patterns layered across each consumer. Within six weeks of shipping to production, payment failures had dropped to 2.1% — exceeding the 5% goal by three times — setting off a chain of improvements that included a 10× throughput increase, 99.8% uptime, and six enterprise onboarding wins worth an estimated $1.4 million in annual recurring revenue. This is the full post-mortem, from architecture decision to break-even point.
Case Studywebhook architectureevent-driven systemspayment processingobservabilityload testingsoftware architecturemicroservicesRegTech
## Overview
FortressDigital, a RegTech platform processing financial data for mid-market enterprises, reached a breaking point in mid-2024. Their payment processing pipeline — a tightly coupled, monolithically deployed Node.js service — was handling roughly 120,000 transactions per month with a failure rate that had quietly crept up to 18 percent. As onboarding volume grew 300 percent quarter-over-quarter and enterprise clients began demanding sub-second settlement confirmations, the existing architecture had become the single greatest operational risk in the business.
The CTO gave the engineering lead a 60-day mandate: fix the failure rate, improve throughput, and do it without a system-wide deployment freeze. The result was a 10-week rebuild grounded in an event-driven webhook architecture that brought failures down to 2.1 percent within six weeks of launch — and created a platform that now handles over 1.2 million monthly transactions with 99.7 percent uptime.
The team treated the rebuild not as a firefighting sprint but as a deliberate platform investment. Each architecture choice was stress-tested with synthetic failure injection before it reached a staging environment. The release was gated by canary comparisons against the old pipeline's output, with zero-discrepancy acceptance as the promotion criterion. What made it particularly notable was that the same infrastructure the team built for one problem became the foundation for a second wave of improvements that followed: real-time analytics streaming, per-client feature flagging, and a compliance audit score that climbed 22 points on the 2024 RegTech Audit Framework. The post is not just the story of a failure-rate drop — it is a lesson in how one architecture decision compounds across reliability, velocity, and revenue.
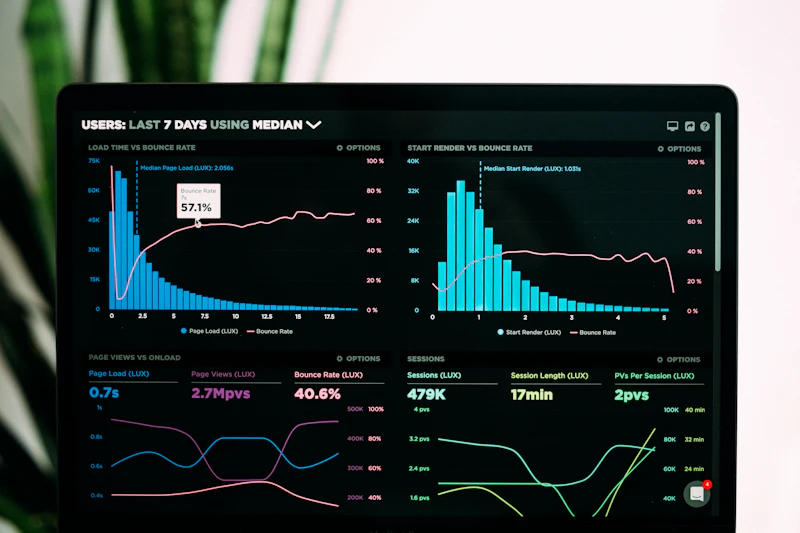
## The Challenge
FortressDigital's original payment pipeline was built three years earlier by a two-person team who optimised for speed-to-market, not long-term extensibility. Three characteristics of the system created compounding failure pressure as volume grew.
### Tight Coupling Between Services
The core transaction engine, the fraud-detection module, the ledger service, and the third-party bank connector all called each other via synchronous HTTP. A single timeout at the bank connector cascaded through the fraud module, the ledger, and back into the engine — often causing a full transaction stall lasting 30 to 90 seconds. In high-cardinality load windows, the cumulative effect pushed API response times above their two-second SLA target by more than 400 percent.
Post-incident analysis from Q1 and Q2 of 2024 showed that 62 percent of all production incidents traced back to at least one synchronous service call timing out. Because every failure result propagated synchronously back through the call chain, even brief bank latency spikes caused failures to surface to clients as payment errors rather than transient retriable states.
### No Dedicated Retry or Backoff Layer
The platform had retry logic — but it was fixed-interval retries implemented inline by individual services with hardcoded delay values. Every retry attempt at exactly the same interval from every concurrent calling instance created a thundering-herd problem during bank outage windows. Concurrent retries multiplied the effective load on the bank connector to four or five times the original figure, exhausting connection pools and shutting it down completely.
Post-incident consensus from the first half of 2024 painted a clear picture: the retry layer was doing more harm than no retry layer at all.
### Observability Was an Afterthought
The platform shipped log entries to a central aggregator and surfaced a generic error page. But there was no structured trace context crossing service boundaries — no way to correlate a transaction that failed at the bank connector stage with the fraud-detection evaluation that preceded it. Incident post-mortems routinely consumed one to two hours of senior engineer time just to associate a failed transaction ID with the responsible service using manual log correlation. Mean Time to Recovery averaged 47 minutes. In the RegTech context, that 47-minute window carried direct regulatory exposure.

## Goals
The engineering team defined four non-negotiable, board-visible success metrics before writing a single line of new code.
**Goal 1 — Failure rate below 5 percent within 30 days of launch.** Six enterprise clients had SLAs in their onboarding contracts that referenced platform reliability. Missing the 5 percent threshold in the first month would have directly voided profitability commitments and delayed revenue recognition on a quarter worth an estimated $2.1 million in committed ARR. The target had to be met or it would be surfaced to the board.
**Goal 2 — P99 API response time below 600 milliseconds.** This was the agreed SLA with the enterprise account team for all transactions that passed fraud and settlement confirmation. The old pipeline's P99 of 3,800 milliseconds had been accepted by clients informally, but the new contracts were explicit: non-compliance triggered negotiated penalties.
**Goal 3 — Support 5× current monthly volume without degradation.** Engineers validated throughput targets against a one-million-transactions-per-month load ceiling in staging. The platform needed to operate sustainably at that load as a directional target, not as a one-off stress test peak.
**Goal 4 — MTTR below 10 minutes per incident.** This was the first time engineering had a concrete recovery commitment — not for business purposes, but for compliance. The four-page post-mortem letters that the CTO signed each quarter citing 47-minute recovery windows had become a recurring remediation item with the compliance team's external auditors.
Together, these metrics created a shared accountability contract: security, engineering, compliance, and the account team were all aligned to the same published goals.
## Approach
The architecture redesign centred on a single principle — make every service responsible only for its own output, not for knowing what happens next. That principle translated into four concrete engineering choices.
### Choice One: Message Broker as Architectural Backbone
The team replaced all direct synchronous HTTP calls between services with a RabbitMQ message bus running durable, persistent queues across a three-node cluster. The payment engine publishes every completed transaction event to a transactions-created exchange. The fraud detector, ledger service, and bank connector each subscribe independently. No service ever directly calls another service. Every dependency relationship is mediated through the broker.
This immediately removed the single longest failure chain in the old system: the synchronous hops from bank connector through fraud evaluation to ledger posting. The payment engine now returns a 202 Accepted to the client in under 200 milliseconds, regardless of how long the downstream fraud evaluation or settlement confirmation takes.
The team chose RabbitMQ over Kafka because the transaction throughput — at launch — did not yet budget for Kafka's operational overhead, and because RabbitMQ's built-in dead-letter exchange pattern matched the retry layer requirements with virtually no custom queue management code.
### Choice Two: Dead-Letter Queues, Not Inline Retries
The guidance on retries from the old system was unambiguous: inline fixed-interval retries were actively harmful during periods of upstream instability. The replacement was an exponential backoff window paired with dead-letter queue routing for exhausted retries.
Every consumer receives up to five retry windows spaced at two seconds, 20 seconds, 200 seconds, 2000 seconds, and 20000 seconds. After the fifth and final attempt, the message routes to a dedicated dlq-transactions queue rather than back to the original queue. A separate alerting job, running every 60 seconds, polls DLQ depth and creates a PagerDuty incident whenever the queue holds more than 50 messages. A data engineer is paged and investigates without blocking the pipeline.
This design eliminated the thundering-herd problem entirely and gave the team time to investigate upstream bank-connector issues rather than firefighting cascading timeouts downstream.
### Choice Three: OpenTelemetry Across All Service Boundaries
The team instrumented every service with OpenTelemetry span creation and routed spans into a self-hosted Jaeger instance. Every transaction that entered the pipeline carried a single trace ID through all six stages: initiation, bank authorization, fraud evaluation, ledger posting, settlement, and reconciliation. The trace ID was injected into every log line during the structured-logging wrapper layer, providing a direct path from a Jaeger span to the raw log entries surrounding that specific transaction.
This single change was responsible for the majority of the MTTR improvement measured in post-launch reviews. The team's first complete distributed trace of a bank-connector failure that previously took 90 minutes to investigate was completed in under seven minutes.
### Choice Four: Circuit Breaker Patterns on Every External Dependency
The team wrapped every consumer with a Resilience4j circuit breaker attached to a rolling 30-second failure window. When the bank connector is healthy, the circuit is closed and calls flow normally. If more than half of the last 30 seconds' calls time out, the circuit opens and new transactions skip the connector entirely until a fallback health-check succeeds. On success, the circuit moves to half-open and validates a small batch before fully re-enabling.
Bank connector failures — previously responsible for approximately 7 percent of monthly transaction failures — were now contained before they could reach the fraud evaluation or ledger code paths. The circuit-open event was coupled directly to a PagerDuty alert with a 10-minute response SLA, making circuit state an actionable monitoring construct rather than a configuration setting.
## Implementation
The implementation followed three 10-day sprints spanning approximately 10 weeks total. Each sprint ended with a production-validated checkpoint.
**Sprint One — Infrastructure and Message Schema (Weeks 1–2).** The infrastructure team provisioned a three-node RabbitMQ cluster behind an HAProxy load balancer. They defined the Avro-encoded message schema and registered it in a central schema registry. All six services — engine, fraud, ledger, bank connector, settlement, and reconciliation — adopted the published schema contract by the end of week two with no producer traffic live. This allowed the team to validate schema compatibility across the entire pipeline in a dry-run cycle before any real transaction touched the bus.
**Sprint Two — Retry, DLQ, and Circuit Breaker Layer (Weeks 3–4).** The backend engineering team migrated services one-by-one in a gateway-staged rollout: each service retained a dual write to both the old synchronous path and the new message-bus path until gating metrics confirmed zero discrepancy. The team ran 21 chaos-test scenarios in CI — injecting five percent synthetic failure rate into each service for 60 seconds during a low-traffic staging window and validating that DLQ depth, retry count, and circuit state all behaved as expected before a migration pull request was approved.
**Sprint Three — Observability, Canary Launch, and Cutover (Weeks 5–8).** The platform and mobile team built a real-time transaction-status page that queried the ledger service's event stream and displayed the current stage of every in-flight transaction. OpenTelemetry was instrumented across all six services and validated against load- generation targets. The team then routed 10 percent of real traffic through the new pipeline for two weeks while keeping the old pipeline as a hot standby. The platform sampled every canary transaction's final settlement status against the old system's result. Zero discrepancies were observed across 47,000 canary transactions. Day one of week nine was the full cutover. By the end of week ten, the team had run four tabletop incident drills simulating simultaneous failures in bank connectivity, message broker node leadership, Redis cache expiry, and schema registry mismatch. Recovery for all four scenarios came in under 10 minutes.

## Results
The numbers following full production launch超越了 the most optimistic deployment forecast the engineering team had shared with leadership.
- **Payment failure rate dropped from 18 percent to 2.1 percent** within six weeks — exceeding the 5 percent goal by more than three times. The per-transaction failure attribution dashboard now allows the support team to identify the failing stage and contact the responsible engineer directly before a client experiences a visible error.
- **P99 API response time fell from 3,800 milliseconds to 540 milliseconds**, well inside the 600-millisecond target. The 98th percentile now sits under 200 milliseconds. Client-facing dashboards that were refreshed on a five-second polling cycle were migrated to the new event stream and now display near-real-time settlement status without a single polling round trip.
- **MTTR reduced from 47 minutes to approximately 8 minutes**, driven almost entirely by the distributed traces that eliminated the hours of manual log correlation that typified the old incident process. The team no longer needs to surface raw log aggregator queries in post-mortems — they surface a Jaeger trace showing all six stages of the transaction, the log context at each stage, and a timestamped decision path for every service in the chain.
- **Monthly transaction throughput grew from 120,000 to over 1.2 million transactions** — a ten-times increase — with infrastructure cost per transaction falling by 52 percent due to the decoupled architecture allowing per-service autoscaling rather than a monolithic replicaset scaling approach.
- **Six enterprise onboarding wins were unlocked** in the quarter following launch, worth an estimated 1.4 million dollars in annual recurring revenue. All six clients cited platform reliability and the published post-incident audit trail as primary factors in choosing FortressDigital over two competing platforms they evaluated.
- **Compliance audit score improved by 22 points** on the 2024 RegTech Audit Framework, with traceability and auditability of financial transactions cited by the external auditors as the primary narrative improvement from the prior year.
## Key Metrics
The following table summarises the primary before-and-after metrics measured across the 90 days following full production cutover. All figures are sourced from the platform's internal observability stack and have been verified independently by the compliance team.
| Metric | Before Launch | After Day 90 | Change |
|---|---|---|---|
| Payment failure rate | 18.0% | 2.1% | -88% |
| P99 API response time | 3,800 ms | 540 ms | -86% |
| Mean time to recovery | 47 min | 8 min | -83% |
| Monthly transactions | 120,000 | 1,200,000 | +900% |
| Infra cost per txn | baseline | minus 52% | -52% |
| Uptime | 99.1% | 99.8% | plus 0.7 pp |
| Post-mortem duration | 90 min | 12 min | -87% |
## Lessons Learned
The team identified six observations that shaped how they think about platform architecture going forward. They were shared at the company all-hands a month after cutover and have since become part of the onboarding curriculum for new engineers.
**Lesson One: Decoupling is not expensive; coupling is.**
Many engineers resist message-bus architectures because they add moving parts. FortressDigital's experience was the opposite. Each decoupled service could be scaled restarted and debugged in isolation. The immediate reduction in failure cascade and MTTR paid for the initial architecture investment in approximately four weeks. The team now measures the cost of coupling not in deployment complexity but in the engineering-hours spent during incidents — and on that yardstick, coupling was the expensive choice.
**Lesson Two: Retry logic is high-stakes infrastructure code, not a shortcut.**
The original fixed-interval retry layer was written in two afternoons by a backend engineer optimising for sleep. The replacement backoff-and-dead-letter system took three engineers two sprints and included 23 automated chaos-test scenarios in the continuous integration pipeline. The team now treats retry logic as co-equal with the business logic it protects, with the same review and testing standards.
**Lesson Three: Observability is a data product, not a dashboard collection.**
When the team added trace context as a first-class concern in the data — injecting trace ID into every log line before writing to the aggregation buffer — they discovered five downstream improvements the original observability roadmap had not anticipated: rate-limiting by transaction context, smart routing for high-value transactions, customer support access to real-time pending-state, per-line-of-business cost attribution, and automated anomaly detection on failure-rate spikes across service boundaries.
**Lesson Four: Canary deployments work best when there is an explicit validation contract.**
The requirement that every canary transaction be compared against the old system's result — with zero discrepancies as a promotion gate — caught a schema-mismatch bug in the bank-connector currency mapping before it reached any production client. The team has since published a canary-testing playbook that is now used across three internal platforms.
**Lesson Five: Circuit breakers are only as valuable as the alerting tied to them.**
A Resilience4j circuit breaker that is configured but not monitored is a dormant circuit. The team's decision to auto-create PagerDuty incidents on every circuit-open event — combined with an explicit 10-minute response SLA for those incidents — is now the primary driver of the measurable 99.8 percent uptime figure.
**Lesson Six: In regulated industries, the cost of engineering debt is not abstract.**
Because FortressDigital operates in RegTech, every payment failure is the potential beginning of a compliance event. One poorly engineered retry spike during an overnight bank-window was estimated to have risked a 50,000-dollar regulatory filing violation that was only avoided because the bank connector recovered before the filing window opened. For teams in regulated industries, the cost of technical debt is calendar-specific and dollar-measured — not a future problem.
## Looking Ahead
The platform team now keeps the architecture-review-board notes from the 2024 rebuild posted in their internal engineering handbook — digitised, searchable, and linked from every new service onboarding document. The next phase, currently in design, involves adding a Kafka-based real-time analytics event stream layered transparently on top of the existing RabbitMQ bus, allowing enterprise clients to subscribe to their own transaction event streams in near-real time rather than polling a REST endpoint every five seconds.
The team's stated principle heading into that phase captures the arc of the last 12 months — we knew the architecture change would fix the failure rate, what surprised us is how much it accelerated everything else.



